Spark核心編程-創(chuàng)新互聯(lián)
- Spark 核心編程
- 一、RDD
- 1、什么是 RDD
- 2、分布式計(jì)算模擬
- (1) 搭建基礎(chǔ)的架子
- (2) 客戶端向服務(wù)器發(fā)送計(jì)算任務(wù)
- 3、RDD 創(chuàng)建
- (1) 從集合(內(nèi)存)中創(chuàng)建
- (2) 從外部存儲(chǔ)(文件)創(chuàng)建RDD
- (3) 從其他RDD創(chuàng)建
- (4) 直接創(chuàng)建 RDD (new)
- 4、RDD 并行度與分區(qū)
- (1) makeRDD() 基于內(nèi)存創(chuàng)建的RDD的分區(qū)
- (2) 基于文件創(chuàng)建的RDD 的分區(qū)
- (3) 數(shù)據(jù)分區(qū)的規(guī)則
Spark 計(jì)算框架為了能夠進(jìn)行高并發(fā)和高吞吐的數(shù)據(jù)處理,封裝了三大數(shù)據(jù)結(jié)構(gòu),用于處理不同的應(yīng)用場(chǎng)景。三大數(shù)據(jù)結(jié)構(gòu)分別是:
1)RDD:彈性分布式數(shù)據(jù)集
2)累加器:分布式共享只寫變量
3)廣播變量:分布式共享只讀變量
接下來(lái)讓我們看看這三大數(shù)據(jù)結(jié)構(gòu)是如何數(shù)據(jù)處理中使用的
RDD(Resilient Distributed Dataset)叫做彈性分布式數(shù)據(jù)集,是 Spark 中最基本的數(shù)據(jù)處理模型。代碼中是一個(gè)抽象類,它代表一個(gè)彈性的,不可變,可分區(qū),里面的元素可并行計(jì)算的集合。
彈性:
存儲(chǔ)的彈性:內(nèi)存與磁盤的自動(dòng)切換
容錯(cuò)的彈性:數(shù)據(jù)丟失可以自動(dòng)恢復(fù)
計(jì)算的彈性:計(jì)算出錯(cuò)重試機(jī)制
分片的機(jī)制:可根據(jù)需要重新分片
分布式:數(shù)據(jù)存儲(chǔ)在大數(shù)據(jù)集群不同的節(jié)點(diǎn)上
數(shù)據(jù)集:RDD 封裝了計(jì)算邏輯,并不保存數(shù)據(jù)
數(shù)據(jù)抽象:RDD 是一個(gè)抽象類,需要子類具體實(shí)現(xiàn)
不可變:RDD 封裝了計(jì)算邏輯,是不可以改變的,想要改變,只能產(chǎn)生新的RDD,在新的RDD里面封裝邏輯計(jì)算
可分區(qū),并行計(jì)算
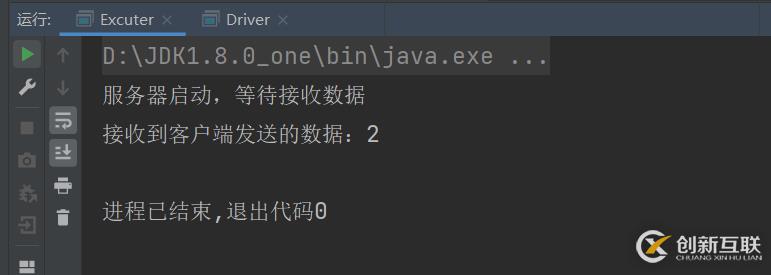
首先分為兩部分,我們把Excuter當(dāng)成服務(wù)器,把Driver當(dāng)成客戶端。然后用客戶端去連接服務(wù)器,然后客戶端發(fā)送數(shù)據(jù)給服務(wù)器。
Excuter (服務(wù)器):
第一步設(shè)置服務(wù)器的端口號(hào),ServerScket(9998)方法,里面的參數(shù)是端口號(hào),這可以隨便寫。然后第二步等待客戶端發(fā)送數(shù)據(jù)過(guò)來(lái)accept()方法。然后第三步使用getInputStream輸入流接收客戶端發(fā)送過(guò)來(lái)的數(shù)據(jù),使用輸入流的read()方法,這個(gè)就是從客戶端拿到的數(shù)據(jù),然后把這個(gè)數(shù)據(jù)給輸出。最后把輸出流,數(shù)據(jù)等待,還有服務(wù)器依次都給關(guān)閉。
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.InputStream
import java.net.{ServerSocket, Socket}
//這個(gè)是做計(jì)算準(zhǔn)備的,主要是邏輯代碼部分
//這個(gè)相當(dāng)于是服務(wù)器,然后Driver相當(dāng)于是客戶端,客戶端連接服務(wù)器就可以直接使用了
class Excuter {}
object Excuter{def main(args: Array[String]): Unit = {//啟動(dòng)服務(wù)器,接收數(shù)據(jù) 這個(gè)端口號(hào)是隨便寫的
val server = new ServerSocket(9998) //這個(gè)是網(wǎng)絡(luò)編程的
println("服務(wù)器啟動(dòng),等待接收數(shù)據(jù)")
//等待客戶端的鏈接
val client: Socket = server.accept() //等待客戶端發(fā)送過(guò)來(lái)的數(shù)據(jù),accept()方法
val in: InputStream = client.getInputStream //輸入流接收數(shù)據(jù)
val i = in.read() //這個(gè)就是拿到的值
println("接收到客戶端發(fā)送的數(shù)據(jù):" + i) //把客戶端拿到的數(shù)據(jù)給輸出
in.close() //把輸入流給關(guān)閉掉
client.close()
server.close() //把服務(wù)器給關(guān)閉掉
}
}
Driver (客戶端):
首先客戶端連接服務(wù)器的端口號(hào)Socket("localhost",9998)方法,第一個(gè)參數(shù)是連接方式,這里是本地連接,第二個(gè)參數(shù)是服務(wù)器的端口號(hào)。然后第二步就向服務(wù)器發(fā)送數(shù)據(jù),getOutputStream方法輸出流,然后使用輸出流的write()方法寫出數(shù)據(jù)。然后使用輸出流的flush()方法,flush方法的作用是,刷新此輸出流并強(qiáng)制寫出所有緩沖的輸出字節(jié)。然后用完之后就把輸出流和客戶端給關(guān)閉了。
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.OutputStream
import java.net.Socket
//這個(gè)是用來(lái)執(zhí)行程序的
class Driver {}
object Driver{def main(args: Array[String]): Unit = {//連接服務(wù)器 本地連接,然后第二個(gè)參數(shù)是服務(wù)器定義的端口號(hào)
val client = new Socket("localhost",9998) //這個(gè)相當(dāng)于是是客戶端,連接服務(wù)器
val out: OutputStream = client.getOutputStream //向服務(wù)器發(fā)東西,用getOutputStream()
out.write(2)
out.flush()
out.close() //用完了吧這個(gè)輸出流給關(guān)掉
client.close() //然后把這個(gè)客戶端也關(guān)掉
}
}Excuter 類里面是服務(wù)器,Driver是客戶端,Task 里面是準(zhǔn)備數(shù)據(jù)和邏輯操作的,那個(gè)Driver 里面創(chuàng)建一個(gè)Task 對(duì)象然后把Task 用ObjectOutputstream輸出流把對(duì)象給輸出到Excuter接收,接收也是使用ObjectIntputstream對(duì)象輸入流進(jìn)行接收,因?yàn)檩敵龅氖且粋€(gè)操作邏輯,用字節(jié)流接收肯定不對(duì),所有要用對(duì)象。然后Excuter 拿到Task之后,就可以直接使用里面的函數(shù)了。Task里面要混入Serializable特質(zhì),因?yàn)樵诰W(wǎng)絡(luò)中肯定是無(wú)法直接傳送一個(gè)對(duì)象過(guò)去的,所以要進(jìn)行序列化。 7
7
Excuter 代碼:
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
//這個(gè)是做計(jì)算準(zhǔn)備的,主要是邏輯代碼部分
//這個(gè)相當(dāng)于是服務(wù)器,然后Driver相當(dāng)于是客戶端,客戶端連接服務(wù)器就可以直接使用了
class Excuter {}
object Excuter{//要混入序列化的特征,不然不能那個(gè)傳一個(gè)對(duì)象過(guò)去
def main(args: Array[String]): Unit = {//啟動(dòng)服務(wù)器,接收數(shù)據(jù) 這個(gè)端口號(hào)是隨便寫的
val server = new ServerSocket(9998) //這個(gè)是網(wǎng)絡(luò)編程的
println("服務(wù)器啟動(dòng),等待接收數(shù)據(jù)")
//等待客戶端的鏈接
val client: Socket = server.accept() //等待客戶端發(fā)送過(guò)來(lái)的數(shù)據(jù),accept()方法
val in: InputStream = client.getInputStream //輸入流接收數(shù)據(jù)
val objin: ObjectInputStream = new ObjectInputStream(in) //輸出流失obj那么接收也應(yīng)該是obj
val task: Task = objin.readObject().asInstanceOf[Task] //這個(gè)就是拿到的值 ,但是這里不應(yīng)該是AnyRef,所以要進(jìn)行轉(zhuǎn)換
val ints = task.compute() //上面已經(jīng)拿到了傳過(guò)來(lái)的操作了,所以可以直接使用里面定義的函數(shù)了
println("計(jì)算節(jié)點(diǎn)的計(jì)算結(jié)果為:" + ints) //把客戶端拿到的數(shù)據(jù)給輸出
objin.close() //把輸入流給關(guān)閉掉
client.close()
server.close() //把服務(wù)器給關(guān)閉掉
}
}Driver 代碼:
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
//這個(gè)是用來(lái)執(zhí)行程序的
class Driver {}
object Driver {def main(args: Array[String]): Unit = {//連接服務(wù)器 本地連接,然后第二個(gè)參數(shù)是服務(wù)器定義的端口號(hào)
val client = new Socket("localhost",9998) //這個(gè)相當(dāng)于是是客戶端,連接服務(wù)器
val out: OutputStream = client.getOutputStream //向服務(wù)器發(fā)東西,用getOutputStream()
val objout = new ObjectOutputStream(out) //定義這個(gè)Object的輸出,因?yàn)樯厦婺莻€(gè)是輸出字節(jié)的不能傳輸對(duì)象
val task:Task = new Task() //然后創(chuàng)建一個(gè)task
objout.writeObject(task) //把task 傳入給objout 對(duì)象輸出流
objout.flush()
objout.close() //用完了吧這個(gè)輸出流給關(guān)掉
client.close() //然后把這個(gè)客戶端也關(guān)掉
println("客戶端發(fā)送數(shù)據(jù)完畢")
}
}Task 代碼:
package com.atguigu.bigdata.spark.core.wc.test2
class Task extends Serializable {//要混入序列化的特征,不然不能那個(gè)傳一個(gè)對(duì)象過(guò)去
val datas = List(1,2,3,4) //這個(gè)是數(shù)據(jù)
val logic = (num:Int) =>{num * 2} //匿名函數(shù) 這個(gè)是邏輯
//計(jì)算
def compute() = {datas.map(logic) //莫logic 上面定義的邏輯操作傳入進(jìn)去
}
}在 Spark 中創(chuàng)建 RDD 的創(chuàng)建方式可以分為四種: 一般就是用前兩種就行了,一般前兩種用的比較多。
(1) 從集合(內(nèi)存)中創(chuàng)建從集合中創(chuàng)建RDD,Spark主要提供了兩個(gè)方法:parallelize和makeRDD
parallelize 是并行的意思,makeRDD 的底層則完全就是調(diào)用了parallelize方法,因?yàn)檫@個(gè)單詞字面意思不大好理解,所以都用makeRDD就行了。
注意:local[*]里面加上*的意思是可以模擬多核多線程,要是不加的話那么就是模擬單線程,從內(nèi)存中創(chuàng)建makeRDD()方法要傳一個(gè)集合進(jìn)去
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.api.java.JavaSparkContext.fromSparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//在內(nèi)存(集合)中創(chuàng)建RDD
class Spark01_RDD_Memory {}
object Spark01_RDD_Memory{def main(args: Array[String]): Unit = {//TODO 準(zhǔn)備環(huán)境
//這個(gè) local[*] 里面加上*的意思是,可以模擬多核多線程,不加的話就是模擬的單線程
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD")
val context = new SparkContext(conf)
//TODO 創(chuàng)建RDD
//從內(nèi)存中創(chuàng)建RDD,將內(nèi)存中集合的數(shù)據(jù)作為處理的數(shù)據(jù)
val seq: Seq[Int] = Seq(1, 2, 3, 4)
//parallelize 并行
//val sc: RDD[Int] = context.parallelize(seq) //這里面?zhèn)魅氲膮?shù)是一個(gè)集合,當(dāng)做數(shù)據(jù)源,
val sc: RDD[Int] = context.makeRDD(seq) //makeRDD方法和parallelize方法是一樣的
sc.collect().foreach(println) //只有觸發(fā)collect方法,才會(huì)執(zhí)行我們的應(yīng)用程序
//TODO 關(guān)閉環(huán)境
context.stop()
}
}由外部存儲(chǔ)系統(tǒng)的數(shù)據(jù)集創(chuàng)建RDD 包括:本地的文件系統(tǒng),所有Hadoop支持的數(shù)據(jù)集,比如HDFS,HBase 等。
注意:這個(gè)文件的路徑,可以是項(xiàng)目目錄下,可以洗本地環(huán)境目錄下,或者說(shuō)hdfs 的路徑下都是可以的。在文件中創(chuàng)建RDD,就要用textFile()方法將文件的路徑給導(dǎo)入進(jìn)去。或者讀取數(shù)據(jù)的時(shí)候用wholeTextFiles()方法可以看到里面的數(shù)據(jù)來(lái)源,具體是來(lái)自于哪一份文件。textFile:以行為單位來(lái)讀取數(shù)據(jù),讀取的數(shù)據(jù)都是字符串wholeTextFIles:以文件為單位讀取數(shù)據(jù),讀取的結(jié)果表示為元組,第一個(gè)元素表示文件路徑,第二個(gè)元素表示文件內(nèi)容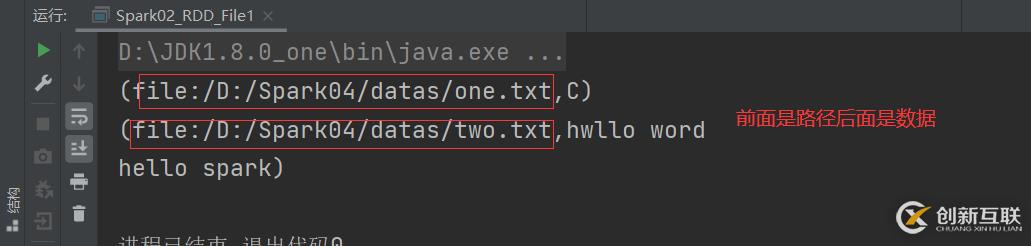
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.{SparkConf, SparkContext}
//從文件中創(chuàng)建RDD
class Spark02_RDD_File {}
object Spark02_RDD_File{def main(args: Array[String]): Unit = {//TODO 準(zhǔn)備環(huán)境
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD_File")
val context = new SparkContext(conf)
//TODO 創(chuàng)建RDD
//從文件中創(chuàng)建RDD,將文件中的數(shù)據(jù)作為處理的數(shù)據(jù)源
//path路徑默認(rèn)以當(dāng)前環(huán)境的根路徑為基準(zhǔn),可以寫絕對(duì)路徑,也可以寫相對(duì)路徑,
//還可以hdfs路徑也是可以的,例如:hdfs://master:9080/test.txt
val file = context.textFile("datas/*")
file.collect().foreach(println)
//TODO 關(guān)閉環(huán)境
context.stop()
}
}主要是通過(guò)一個(gè)RDD運(yùn)算完后,再產(chǎn)生新的RDD。
(4) 直接創(chuàng)建 RDD (new)使用new的方式直接構(gòu)造 RDD,一般由 Spark 框架自身使用。
4、RDD 并行度與分區(qū)默認(rèn)情況下,Spark 可以將一個(gè)作業(yè)切分多個(gè)任務(wù)后,發(fā)送給Executor 節(jié)點(diǎn)并行計(jì)算,而能夠并行計(jì)算的任務(wù)數(shù)量我們稱之為并行度。這個(gè)數(shù)量可以在構(gòu)建RDD時(shí)指定。記住,這里的并行執(zhí)行的任務(wù)數(shù)量,并不是指的切分任務(wù)的數(shù)量,不要混淆了。
(1) makeRDD() 基于內(nèi)存創(chuàng)建的RDD的分區(qū)注意:makeRDD()方法,第二個(gè)參數(shù)是個(gè)隱式參數(shù),是分區(qū)的數(shù)量,如果不傳的話那么默認(rèn)分區(qū)跟本地環(huán)境的核有關(guān)。比如我的電腦是4核,那么分區(qū)就是分為四個(gè),并行計(jì)算。saveAsTextFile()方法 將處理的數(shù)據(jù)保存成分區(qū)文件,里面的參數(shù)是要?jiǎng)?chuàng)建的文件名。然后輸出之后會(huì)自動(dòng)生成一個(gè)這個(gè)名字的目錄,下面的文件是分區(qū)文件。
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//RDD 并行度
class Spark01_RDD_Memory_Par {}
object Spark01_RDD_Memory_Par{def main(args: Array[String]): Unit = {//TODO 準(zhǔn)備環(huán)境
//這個(gè) local[*] 里面加上*的意思是,可以模擬多核多線程,不加的話就是模擬的單線程
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD")
val context = new SparkContext(conf)
//TODO 創(chuàng)建RDD
//RDD的并行度 & 分區(qū)
//makeRDD 方法可以傳入第二個(gè)參數(shù),第二個(gè)參數(shù)是分區(qū)的數(shù)量
//第二個(gè)參數(shù)是可以不傳的,因?yàn)槭请[式參數(shù),如果不傳默認(rèn)分區(qū)就是按照內(nèi)核數(shù)量決定的,我的內(nèi)核是4個(gè),所以分區(qū)是4
val rdd:RDD[Int] = context.makeRDD(List(1, 2, 3,4,5),3) //里面的第一個(gè)參數(shù)是一個(gè)集合,第二個(gè)參數(shù)是分區(qū)的數(shù)量,分為幾個(gè)區(qū)
//saveAsTextFile方法 將處理的數(shù)據(jù)保存成分區(qū)文件
rdd.saveAsTextFile("output")//saveAsTextFile方法
//TODO 關(guān)閉環(huán)境
context.stop()
}
}它分區(qū)分配數(shù)據(jù)的方式和Hadoop的分區(qū)的方式是一樣的。和上面的基于內(nèi)存的分配數(shù)據(jù)的方式不一樣。
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class Spark02_RDD_File_Par {}
object Spark02_RDD_File_Par{def main(args: Array[String]): Unit = {//TODO 準(zhǔn)備環(huán)境
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD_File2")
val context = new SparkContext(conf)
//TODO 創(chuàng)建RDD
//textFile 可以將文件作為數(shù)據(jù)處理的數(shù)據(jù)源,默認(rèn)也可以設(shè)定分區(qū)
// minPartitions:最小分區(qū)數(shù)量
//默認(rèn)分區(qū)是兩個(gè),如果不想使用默認(rèn)的分區(qū)數(shù)量那么,可以通過(guò)第二個(gè)參數(shù)指定分區(qū)數(shù)
val rdd: RDD[String] = context.textFile("datas/one.txt",3)
rdd.saveAsTextFile("output")
//TODO 關(guān)閉環(huán)境
context.stop()
}
}首先看字節(jié),可以看到這個(gè)文件一共是14個(gè)字節(jié),加上回車符
然后我們分兩個(gè)區(qū),14 / 2 = 7,一個(gè)區(qū)是7個(gè)字節(jié),再用 14 / 7 = 2 可以看到剛好是2沒(méi)有余數(shù),所以沒(méi)有問(wèn)題剛剛好。首先是要計(jì)算行偏移量,計(jì)算出第一行的行偏移量是多少,計(jì)算出第二行是多少,然后計(jì)算行偏移量的范圍就可以算出每個(gè)分區(qū)得到的數(shù)據(jù)是什么了。
查看結(jié)果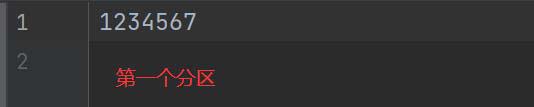
你是否還在尋找穩(wěn)定的海外服務(wù)器提供商?創(chuàng)新互聯(lián)www.cdcxhl.cn海外機(jī)房具備T級(jí)流量清洗系統(tǒng)配攻擊溯源,準(zhǔn)確流量調(diào)度確保服務(wù)器高可用性,企業(yè)級(jí)服務(wù)器適合批量采購(gòu),新人活動(dòng)首月15元起,快前往官網(wǎng)查看詳情吧
新聞名稱:Spark核心編程-創(chuàng)新互聯(lián)
文章鏈接:http://www.2m8n56k.cn/article28/ccesjp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站建設(shè)、App開(kāi)發(fā)、定制開(kāi)發(fā)、企業(yè)建站、建站公司、關(guān)鍵詞優(yōu)化
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:[email protected]。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 快速了解Druid——實(shí)時(shí)大數(shù)據(jù)分析軟件-創(chuàng)新互聯(lián)
- 如何使自己的網(wǎng)頁(yè)打開(kāi)更快?-創(chuàng)新互聯(lián)
- Bee.WeiXin微信框架的使用方法-創(chuàng)新互聯(lián)
- shell中常用的vi編輯命令有哪些-創(chuàng)新互聯(lián)
- Tomcat下載安裝-創(chuàng)新互聯(lián)
- Servlet學(xué)習(xí)筆記-創(chuàng)新互聯(lián)
- js之切換全屏和退出全屏實(shí)現(xiàn)代碼實(shí)例-創(chuàng)新互聯(lián)

- 用戶體驗(yàn)其實(shí)就這么簡(jiǎn)單! 2022-06-07
- 品牌網(wǎng)站設(shè)計(jì)的流程有哪些 2023-02-13
- 我要做的是品牌網(wǎng)站設(shè)計(jì),實(shí)際上是品牌網(wǎng)頁(yè)優(yōu)化設(shè)計(jì),可懂? 2022-05-23
- 品牌網(wǎng)站設(shè)計(jì)都需要一個(gè)“新聞工具包” 2023-03-02
- 如何做好網(wǎng)站設(shè)計(jì)?企業(yè)品牌網(wǎng)站設(shè)計(jì)重要指南 2022-08-16
- 品牌網(wǎng)站設(shè)計(jì)怎樣做更加高端? 2022-11-15
- 金融網(wǎng)站建設(shè)競(jìng)爭(zhēng)力,品牌網(wǎng)站設(shè)計(jì)新趨勢(shì) 2014-06-08
- 深圳品牌網(wǎng)站設(shè)計(jì)公司 2014-05-13
- 深圳福田網(wǎng)站設(shè)計(jì)與制作,品牌網(wǎng)站設(shè)計(jì)制作的步驟是什么? 2021-11-20
- 深圳品牌網(wǎng)站設(shè)計(jì):如何制作設(shè)計(jì)一個(gè)好的網(wǎng)站 2021-08-17
- 理解透公司品牌內(nèi)涵后才能做好品牌網(wǎng)站設(shè)計(jì)制作 2022-04-05
- 優(yōu)秀品牌網(wǎng)站設(shè)計(jì)欣賞 2014-06-25